Lidar com o volume de publicações e intimações é um dos maiores desafios na rotina de um escritório de advocacia. Uma complicação natural desse processo é a duplicidade de registros, que pode ser gerada pelos próprios tribunais ao realizar publicações em diferentes fontes. Isso polui a fila de trabalho, consome tempo valioso da equipe e aumenta o risco de erros manuais.
Para otimizar essa tarefa, desenvolvemos uma nova funcionalidade que identifica, correlaciona e facilita o tratamento de publicações duplicadas de forma segura e eficiente.
O Desafio: Duplicidade Real vs. Publicações Diferentes
Nosso principal desafio era claro: como podemos, com segurança, diferenciar uma publicação genuinamente duplicada de uma publicação nova e diferente, mas que foi emitida no mesmo dia e para o mesmo processo? Tratar um conteúdo novo automaticamente como se fosse duplicado representa um risco operacional.
A Solução: Correlação por Dados e Similaridade por Conteúdo
A nova ferramenta ataca esse problema com uma abordagem em duas etapas, garantindo segurança e agilidade:
- Correlação de Dados: Primeiramente, o sistema varre e agrupa automaticamente todas as publicações/intimações que possuem o mesmo número de processo e a mesma data de publicação.
- Cálculo de Similaridade: Após agrupar, o sistema realiza um cálculo avançado de similaridade. Ele compara o conteúdo de cada publicação correlacionada e atribui um “score” percentual (de 0 a 100%) que indica o quão idênticas elas são.
É fundamental destacar: o sistema não lê ou descarta publicações automaticamente. Ele organiza a informação e fornece as ferramentas para que você possa tomar a decisão de leitura de forma muito mais rápida e embasada.
Como Funciona o Cálculo de Similaridade? (Detalhe Técnico)
Explicação não técnica: O cálculo simplesmente compara os conteúdos e gera a porcentagem de semelhança.
Explicação técnica: Transformamos os conteúdos das publicações em Embeddings (uma representação vetorial do conteúdo). Em seguida, é calculado o cosseno entre os vetores de cada conteúdo. Vetores muito similares possuem um cosseno próximo de 1. O sistema então multiplica esse resultado por 100 para gerar a taxa de similaridade que você vê na tela.
Na Prática: Identificando as Publicações na sua Fila
Ao acessar sua lista de publicações, você notará duas novas tags visuais que organizam os registros:
1. Publicações que Possuem Relacionadas (Tag Azul – A “Principal”)
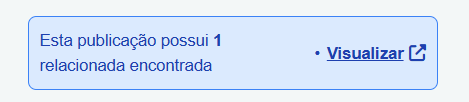
Esta tag indica que esta é a “primeira ocorrência” de uma série de duplicidades.
- O que ela exibe: Um campo azul acima do conteúdo, indicando quantas publicações relacionadas (duplicadas) ela possui (ex: “Esta publicação possui 4 relacionadas”).
- Ação de Validação: Ao clicar em “visualizar” nesta tag, o sistema abre uma nova aba já com a lista filtrada, mostrando apenas as publicações duplicadas vinculadas a ela. Isso permite uma conferência rápida, se necessária.
2. Publicações Relacionadas à Primeira Ocorrência (Tag Amarela – A “Duplicada”)

Esta tag identifica uma publicação que o sistema calculou ser uma duplicata de outra já existente.
- O que ela exibe: Um campo amarelo acima do conteúdo, mostrando:
- A porcentagem de semelhança (ex: “Há 99,7% de chance de esta publicação ser relacionada a…”).
- Um link com o código da publicação “Principal” (tag azul) à qual ela está vinculada.
- Observação: Em geral, estas publicações chegam ao sistema depois da primeira ocorrência.
O Ganho de Produtividade: Leitura em Massa
A principal vantagem da funcionalidade está em como você trata as publicações “Principais” (tag azul).
Ao marcar como lida uma publicação que possui relacionadas (tag azul), o sistema proativamente oferecerá uma ação em massa. Isso funciona em dois momentos:
- Ao clicar no ícone de “leitura” (Marcar como lida) na listagem.
2. Ao clicar em “Salvar e Marcar como Lida” dentro da tela de agendamento de tarefa.

Em ambos os casos, um pop-up perguntará: “Deseja marcar todas as publicações relacionadas como lidas?”
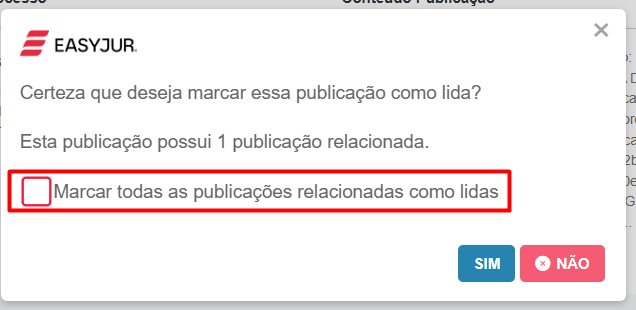
Ao marcar o checkbox e confirmar, o sistema marca automaticamente a publicação principal E todas as suas relacionadas (duplicadas) como “LIDA”, limpando sua fila de trabalho de uma só vez.
Ponto Importante: Se você marcar uma publicação Relacionada (tag amarela) como lida, o sistema entenderá como uma ação individual e não oferecerá a leitura em massa. O fluxo de trabalho ideal é sempre focar nas publicações de tag azul.
Gerenciando sua Fila: Os Novos Filtros de Visualização
Para dar controle total sobre a exibição, o menu dropdown de filtros de publicações foi atualizado com novas opções:
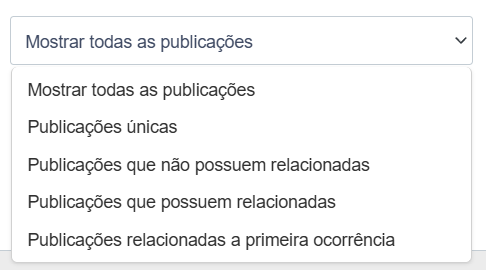
- Mostrar Todas as Publicações:
Lista todas as publicações (principais, relacionadas e únicas), permitindo a aplicação de outros filtros de data, processo, etc. - Publicações únicas:
Este filtro exibe as publicações “Principais” (azuis) + as publicações que “Não possuem relacionadas”. Na prática, ele esconde todas as duplicadas (amarelas) da sua tela, fornecendo a visão mais limpa da fila de trabalho. - Publicações que não possuem relacionadas:
Lista apenas as publicações que não estão e nem possuem qualquer relação com outras. - Publicações que possuem relacionadas:
Este é o filtro de produtividade. Ele lista apenas as publicações “Principais” (tag azul). O fluxo ideal é usar este filtro e ir tratando as publicações, realizando a leitura em massa. - Relacionadas a primeira ocorrência:
Lista apenas as publicações duplicadas (tag amarela). É útil para auditoria ou conferência.
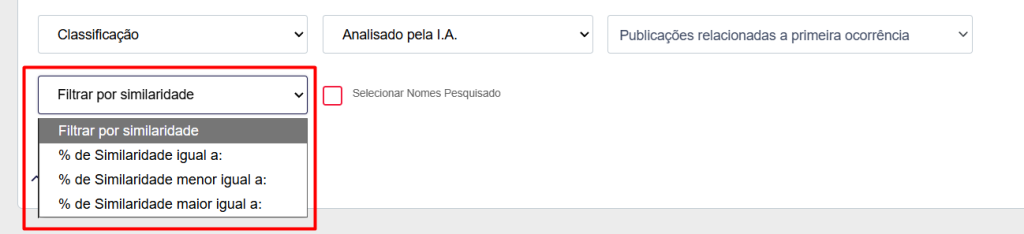
Filtro Avançado: Controle Total com o Score de Similaridade
Levamos o controle do escritório a um novo nível. Ao selecionar o filtro Relacionadas a primeira ocorrência (mostrando apenas as duplicadas de tag amarela), um novo filtro avançado aparecerá: Filtrar por similaridade.
Este filtro permite que você defina suas próprias regras de negócio, com as seguintes opções:
- % de similaridade igual a:
- % de similaridade menor que:
- % de similaridade maior que:
Basta escolher a opção e inserir a porcentagem desejada.

Qual o propósito deste filtro?
Dar autonomia para o escritório criar seus próprios parâmetros de validação e confiança.
- Exemplo 1 (Tratamento em Massa): O escritório pode definir sua política: “Considero seguro tudo que tiver similaridade maior que 90%“. O usuário pode aplicar esse filtro, selecionar todas e marcar como lidas em massa.
- Exemplo 2 (Investigação): O escritório pode querer investigar casos duvidosos: “Quero ver tudo com similaridade menor que 50%, pois pode indicar que, na mesma data, o processo teve mais de uma publicação diferente que exige atenção.”
Em síntese, esta nova funcionalidade ataca diretamente um dos maiores gargalos de produtividade dos escritórios: o ruído gerado por publicações duplicadas pelos tribunais ao disponibilizar o mesmo conteúdo em mais de um diário oficial. Ao combinar a correlação automática de dados com um cálculo avançado de similaridade, a ferramenta oferece segurança para diferenciar duplicatas reais de publicações distintas. O verdadeiro ganho, no entanto, está na agilidade operacional, permitindo a leitura em massa das duplicatas e na flexibilidade dos novos filtros, que dão autonomia para o escritório definir suas próprias regras de validação. O resultado é uma fila de trabalho drasticamente mais limpa, menor risco de erro humano e uma equipe jurídica focada na análise estratégica, em vez de em tarefas manuais repetitivas.